Semantic Search
A search technique that understands the meaning and intent behind queries rather than matching exact keywords, using vector embeddings to find conceptually relevant results even when different words are used.
Why it matters
Semantic search enables AI systems to find relevant information even when users don't use the exact right words — critical for RAG and knowledge management.
How Semantic Search Differs from Keyword Search
Traditional keyword search (sometimes called lexical search) works by matching the exact words in your query against an index of documents. If you search for "car maintenance tips," it won't find a document titled "vehicle servicing guide" — even though they're about the same thing. Semantic search closes this gap by working with meaning rather than surface-level text.
Instead of building an inverted index of words, semantic search converts both queries and documents into dense vector representations (embeddings) that capture conceptual meaning. Two pieces of text about the same topic will have vectors that are close together in this high-dimensional space, regardless of the specific words used.
How It Works
The process follows a straightforward pipeline:
- Embedding generation — An embedding model (like OpenAI's text-embedding-3-small or open-source alternatives like BGE) converts text into fixed-length vectors, typically 768 to 3072 dimensions.
- Indexing — Document embeddings are stored in a vector database (Pinecone, Weaviate, pgvector) with approximate nearest neighbor (ANN) indexes for fast retrieval.
- Query-time similarity — The user's query is embedded with the same model, and cosine similarity (or dot product) identifies the closest document vectors.
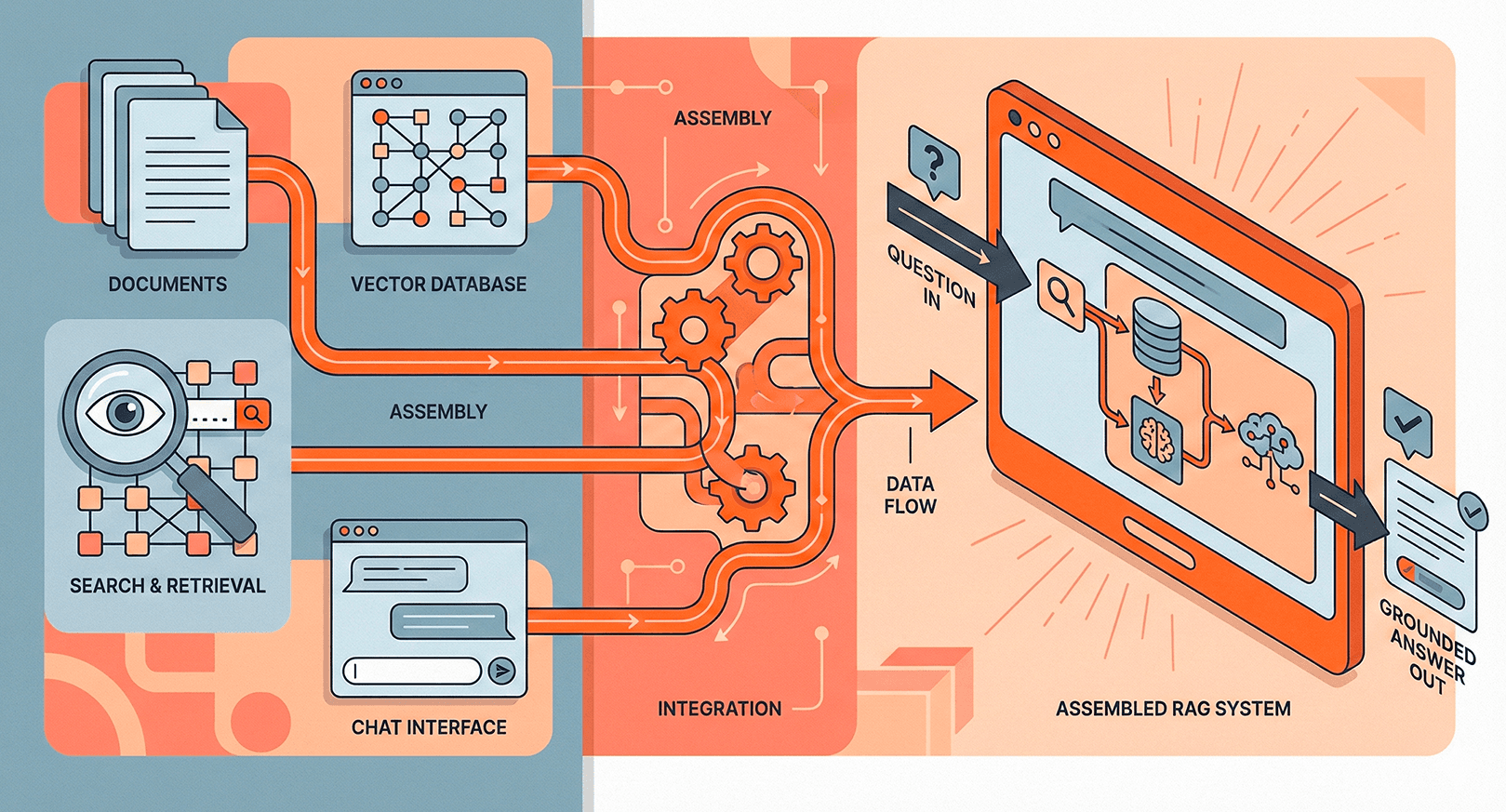
Role in RAG Pipelines
Semantic search is the retrieval backbone of most Retrieval-Augmented Generation systems. When a user asks a question, the RAG pipeline uses semantic search to find the most relevant chunks from a knowledge base, then feeds those chunks as context to a large language model. The quality of this retrieval step directly determines whether the LLM gets the right information to generate an accurate answer. Poor retrieval means the model either hallucinates or gives generic responses — no amount of prompt engineering can fix bad context.
Related terms