Retrieval-Augmented Generation
A technique that grounds a language model's output in external data by retrieving relevant documents before generating a response.
Why it matters
RAG is the most practical way to give an LLM access to your private data without fine-tuning. It is the foundation of most enterprise AI deployments today.
How it works
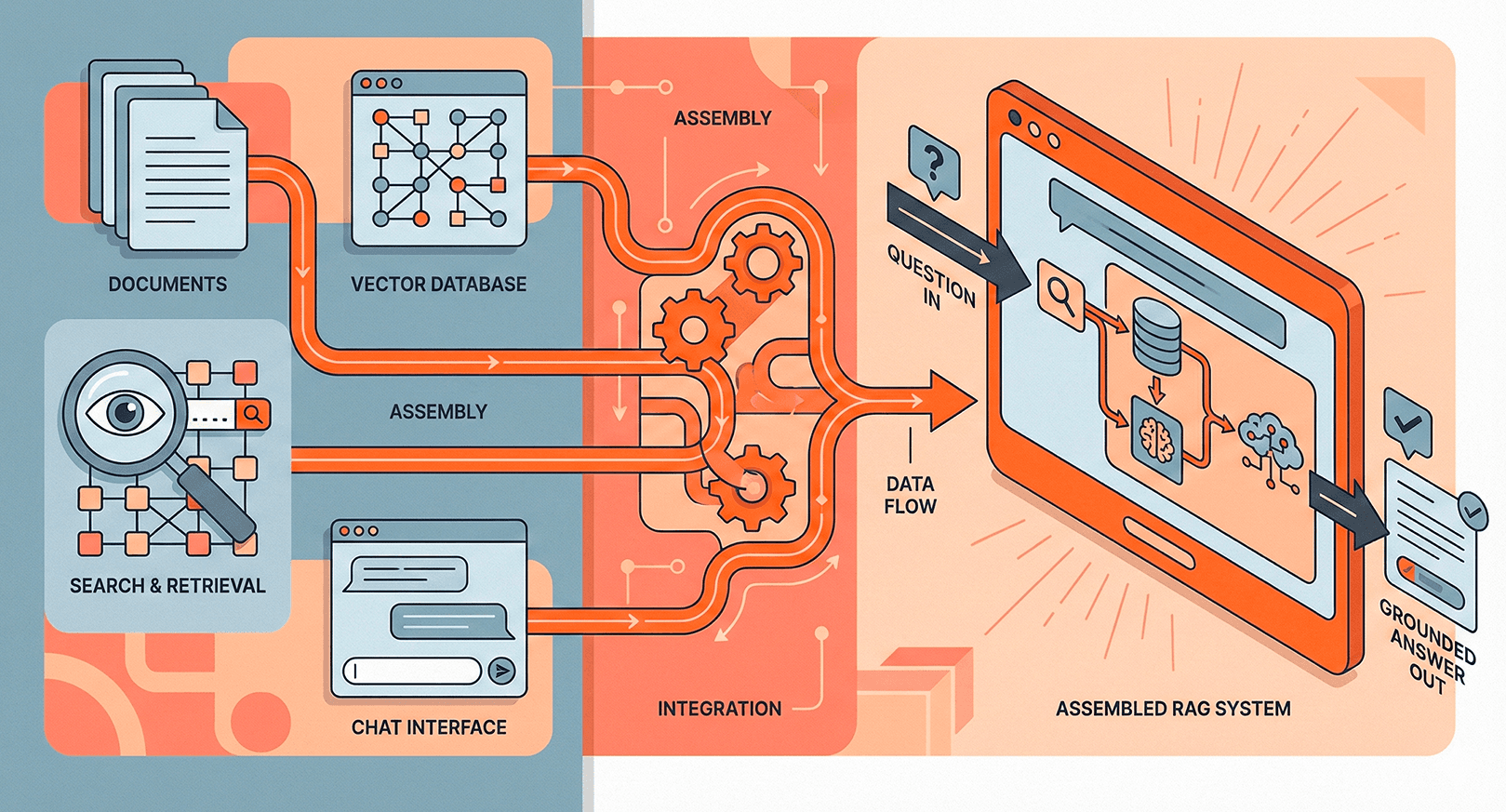
RAG pipelines typically follow a three-step process: index documents into a vector store, retrieve the most relevant chunks at query time, and augment the LLM prompt with those chunks so the model can cite real sources instead of hallucinating.
Key variations
The basic retrieve-then-read pattern has evolved into several specialized variants:
- Naive RAG — single retrieval pass, straightforward but limited for complex queries.
- Agentic RAG — an LLM decides when and what to retrieve, routing queries and iterating on results.
- GraphRAG — combines vector retrieval with knowledge graph traversal for relationship-aware answers.
- Contextual Retrieval — prepends document-level context to each chunk before embedding, dramatically improving recall.
Common pitfalls
Poor chunking strategy is the number one source of bad RAG quality. Splitting on arbitrary token counts loses semantic coherence. Use semantic chunking or document-aware splitting instead. Also monitor retrieval recall — if the right documents aren't in the top-k results, no amount of prompt engineering will fix the output.
Related terms