Embeddings
Dense numerical representations of text (or other data) in a high-dimensional vector space, where similar meanings are placed closer together.
Why it matters
Embeddings are the bridge between human language and machine computation. They power semantic search, RAG, recommendations, and virtually every AI feature that needs to understand meaning.
How embeddings work
An embedding model converts a piece of text — a word, sentence, or document — into a fixed-length array of floating-point numbers (typically 768–3072 dimensions). The model is trained so that semantically similar inputs produce vectors that are close together, measured by cosine similarity or dot product.
Use cases
- Semantic search — find documents by meaning, not just keywords.
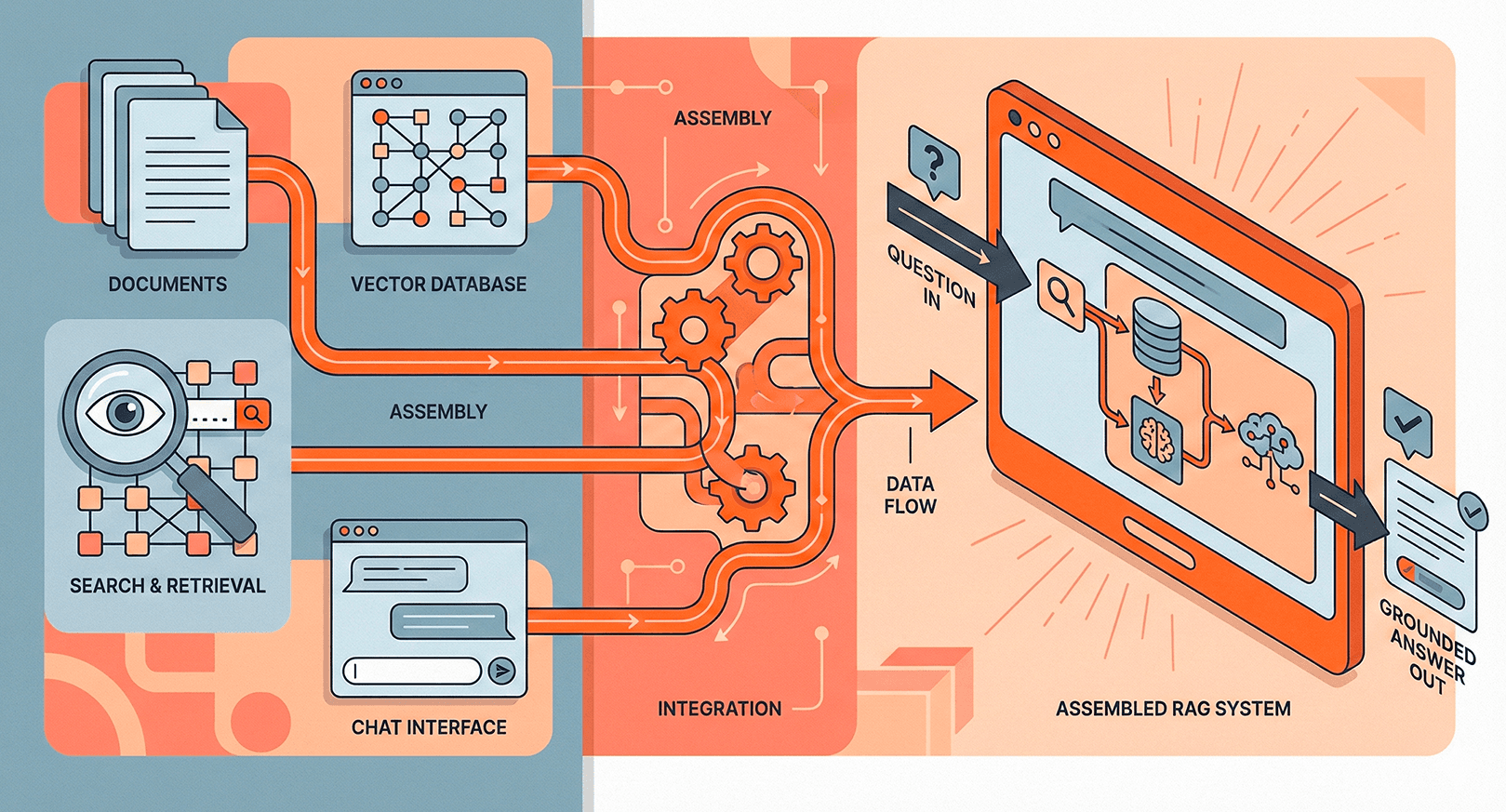
- RAG retrieval — the retrieval step in RAG pipelines relies on embedding queries and documents into the same vector space.
- Clustering & classification — group similar items or train lightweight classifiers on top of embeddings.
- Anomaly detection — identify outliers in vector space.
Choosing an embedding model
Key factors: dimensionality (higher = more expressive but slower), context window (how much text it can embed at once), and domain fit. Popular choices include OpenAI's text-embedding-3, Cohere Embed v3, and open-source models like E5 and BGE.
Related terms